Train, Deploy and Track a Keras Image Classifier with MLflow
Train and Deploy Keras Image Classifier with MLflow
- Objective
- Start MLFlow Tracking Server
- Train a Flower Classifier model
- Run Training
- MLflow Tracking
- MLflow Artifact Repository
- Deploy the Model
- Test deployed Model
- Possible Errors
Objective
Objective of this post:
- Execute a training and deployment cycle using MLFlow as tool
- Discuss pre-requisities for using MLFlow to train and deploy model
- See the experiment results in MLFlow Tracking and artifacts in AWS S3
- List down possible major errors while following along this post
This post is not intended to explain ML Engineering for flower classification using keras.
Use MLFlow official github as reference along with this article.
I am using an AWS g4dn.xlarge instance for this demonstration.
Start MLFlow Tracking Server
Conda virtual environment is used in this demonstartion to execute training and deployment. Follow this link if you need help in creation and management of conda environment.
Create a new conda environment and follow the instructions provided here to start MLFlow Tracking server with Postgresql as entity store and S3 as Artifact store.
After completing above steps, MLFlow tracking will be available in http://ip-address:5000 Go ahead and access the url to make sure tracking server is up and running.
Train a Flower Classifier model
Clone the official MLFLow repo. The repo includes many examples for trying out various features of MLFlow. For our demo purpose, I am going to use Flower Classifier example. The example is placed in example\flower_classifierdirectory in the repo. The directory is organized as a MLflow Project. In this example, a VGG16 deep learning model is trained to classify flower species from photos using a dataset available from tensorflow.org. Keras is used to train the model.
About MLflow Project
MLflow project is a convention to organize code for users and tools to understand and process machine learning code. An elaborate description of MLflow Project is given in the MLflow official docs.
Any git repo or folder can work as MLflow Project and any python or bash script can work as entry point of the project. MLflow projects include python based API and Command-line tools for running projects. In this demo, command-line tool is utilized to execute project.
MLflow project entrypoint can be further controlled by including a MLproject file in the MLflow Project directory.
MLflow project can run in Conda, Docker or System environment. In this demonstartion conda environment is used for execution. The conda environment is specified in conda.yaml file within the project directory. The project entry point and parameters are specified in the MLproject file.
Run Training
Note: make sure to update
MLFLOW_TRACKING_URIenvironment variable with the MLFlow Tracking server information e.g. http://ip-address:5000
Execute training from command-line:
mlflow run examples/flower_classifier
This creates a conda virtual environment for training our model.

After successful completion of training, mlflow generates a run id.

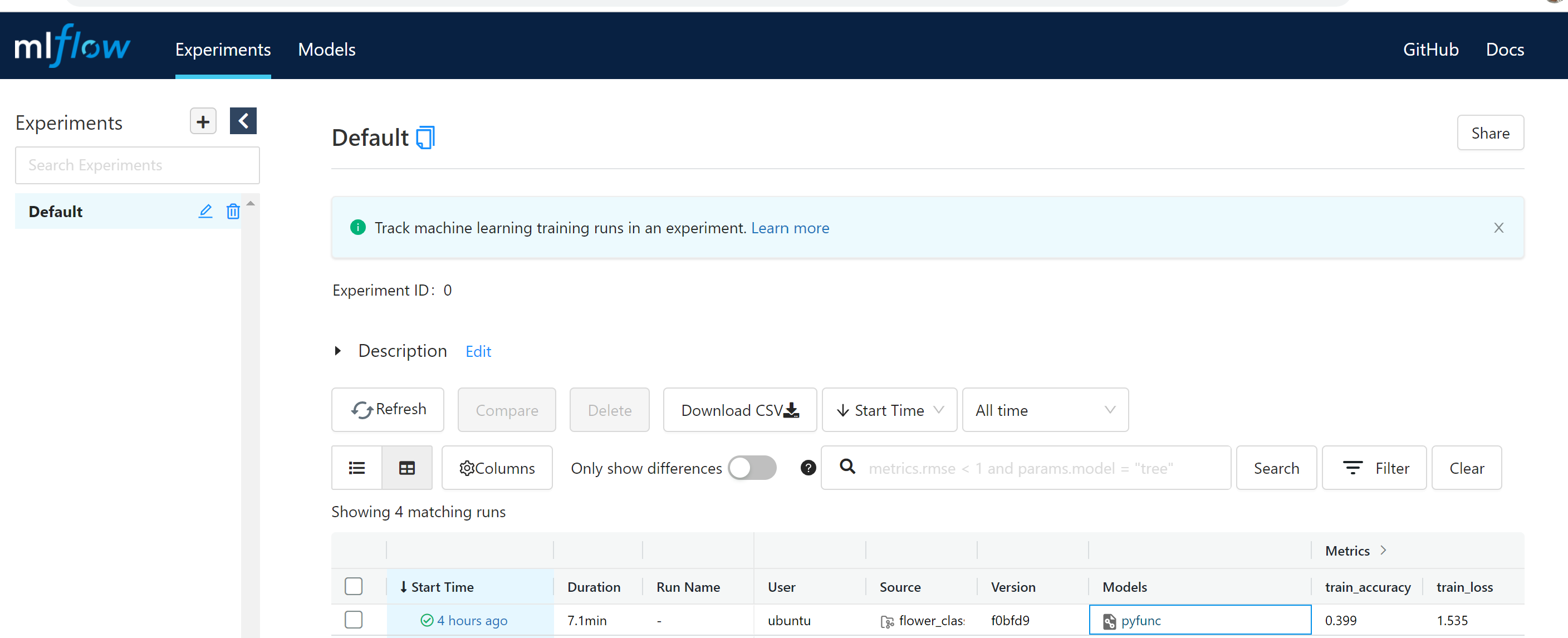
MLflow Tracking
Open the tracking URI at http://ip-address:5000 and check the training parameters logged.
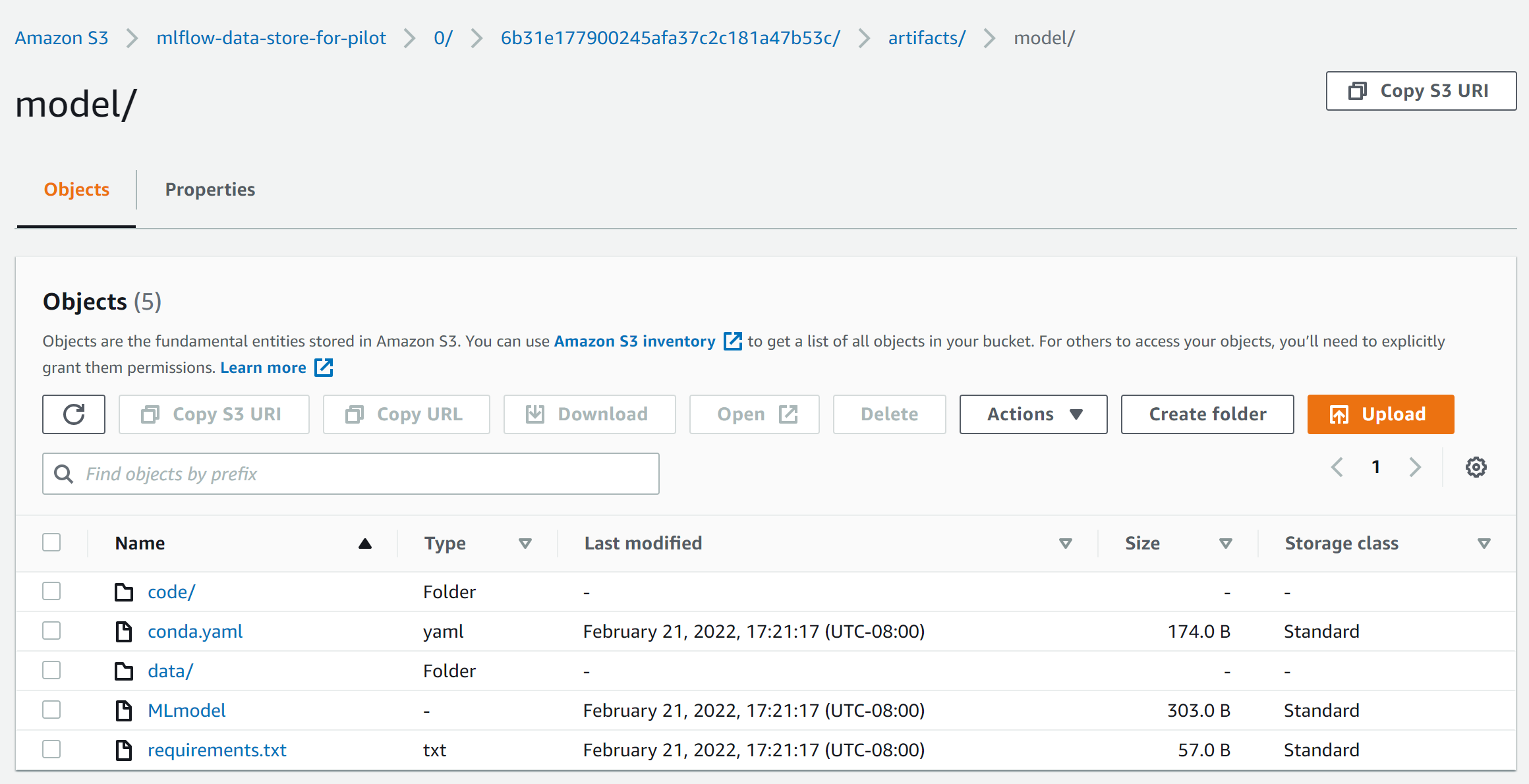
MLflow Artifact Repository
MLflow model created by the training is stored in AWS S3.
MLflow Model
MLflow model is a format of packaging ML Models that can be used by various tools for serving, for example, by an API or by a batch inference system. The format defines a convention to save models in different flavors to support different downstream tools.
MLflow model is a directory with some relevant files in the directory . The MLmodel file in the root directory defines the different flavors the model can be viewed in. Refer to official MLflow doc for details on MLflow Model.
An example of MLmodel file where model is available as python function
artifact_path: model
flavors:
python_function:
code: code
data: data/image_model
env: conda.yaml
loader_module: image_pyfunc
python_version: 3.7.12
model_uuid: ef9a1e89fbcd44a69cebd9888f684561
run_id: 6b31e177900245afa37c2c181a47b53c
utc_time_created: '2022-02-22 01:21:14.789377'
Deploy the Model
Deploy the model from the tracking server REST endpoint by executing mlflow models serve. The run id created during the training is used to refer the model to serve.
This also creates a separate conda virtual environment for deployment purpose.

Test deployed Model
Go to directory where score_images_rest.py is placed and run the script with test image as an argument


The model runs on the passed flower image and predicts which flower it is!
Possible Errors
Following errors may appear while completing the training and deployment
AttributeError: 'str' object has no attribute 'decode'
While model serving, this error occurs if version of installed h5py package version > 3.
Downgrade the version of h5py to 2.10.0 by running pip install h5py==2.10.0 in the conda virtual environment for deployment and that should solve this problem.
ModuleNotFoundError: No module named 'boto3'
This error occurs during mlflow run if the virtual environment does not contain boto3. Install boto3 package and retry.